今天大家很快地將作業紙本繳給老師,讓Dr.Foster可以準時上課,本週上課的重點是說明實地研究法及選出五個主題讓同學進行分組作業,老師上課的內容真的很充實,四小時只能算勉強上完,所以把握最後的時間趕緊分組,雖然老師很想看見大家討論的情形,但是怕課上不完,所以就請同學將討論時間跟老師說,老師再陪同出席,沒辦法陪同的小組再錄音錄影。
感想:
今天上實地研究,一開始老師就告訴我們,質化研究的觀察重點和量化研究最大的不同,在於質化研究觀察自然情境;量化研究觀察設計的/控制的現象。質化研究講求意義解讀,剛好那時有同學提問:「質化研究是先觀察,再提出研究問題嗎??」那時我就不加思索地說「我覺得質化研究也是先提出研究問題再去觀察,只是在觀察的當中不要注入過多的外在因素,一切都是在很自然的狀況下產生」(心中os:我要知道醫病關係,所以才進入醫院的場域觀察,醫病關係不就是我的研究問題嗎?)
美美老師以阿亮論文為例,並解釋「想了解的那不是研究問題,而是觀察後提出的疑問才是研究問題」,這是我的第一顆質化炸彈。隨著課堂中Dr.Foster持續講授,質化研究也似乎一層層撥開面紗。(不過說實在的,比先前的課程容易理解,可能是有例子而且也比較貼近我們吧!)
分享:
老師課堂上有提到葉老師進入場域的經驗。在這邊也跟大家分享,我進入原住民朋友圈的經驗。於公於私我認識很多原住民朋友(有超過10個吧,且分屬不同族),剛開始認識時,彼此間都維持著一個禮貌的距離,後來常常交談發現我其實無害而且還有益,就開始接納我。雖然剛開始我是個別認識一兩位,但當其中一位帶我進入他的朋友圈時,其他原住民朋友就很快地接納我。他們相當好客,那陣子我講話的口音也不知不覺中像起原住民。(不過在這邊要告訴大家,原住民不會覺得你學他們講話,或講話像他們,就接納你喔!)
重點概要:
1、質化/量化:質化研究的觀察重點和量化研究最大的不同,在於質化研究觀察自然情境;量化研究觀察設計的/控制的現象。質化研究講求意義解讀,在自然情境中觀察(observation)和推論(infernces),觀察具體事實,研究者進一步從觀察產生推論,再進一步由訪談來證實研究者的推論。
2、霍桑效應:是說當人們知道自己成為觀察對象,而改變行為的傾向。
(進入場域,讓場域的人們習慣研究者的存在,或不要對單一對象過於關注,應該可以避免這樣的效應)
3、進場/出場:進入和離開場域,要慎選時機,而且要注意自己不要被同化。老師上課中很強調的一環,還舉了一個研究上班小姐的例子,真的是為研究很攜牲,但我不禁想要問那些不知情把她當麻吉的被研究上班小姐,發現實情會如何做想。(東海社研所 十二個上班小姐的生涯故事)
4、筆記:田野筆記有分jotting notes(隨筆,為避免觀察者感覺不舒服,可隨手記下多為一簡短的詞)、direct observation(直接觀察,離開實地後所寫下的筆記,為一詳細的描述)、inference(推論,重讀直接觀察的筆記時找出的多種意義)、analytic(分析,分析推論的原因)、personal journal(個人筆記,抒發個人情感或個人反應)
練習題:
1、圖書館民族誌
2、團體討論/記錄團體討論中個人反應
ps.Dr.Foster的課堂作業相較於其他老師算是多的,但甘之如飴,有練習才有收穫^^
Oct 30, 2008
LIS 97.10.24
本週邀請蔡明月老師做有關於資訊計量學的講授,由於大部份的同學都是第一次接觸資訊計量學,所以老師花了一些時間為大家說明相關名詞及遞嬗,最後才進入學術引文的簡報。
數據的愛恨情愁
學術生產力、引用率、期刊影響指數在近年一直是很HOT的議題,當別人問起你的研究能力如何?這個往往就是最好的證明,醫師、教授升等都需要依賴它,但人們熱愛數據卻也痛恨數據,數據的計算及收錄的標準等背後都隱藏著計多力量在互相拉扯。
學門的焦慮
雖然老師是針對資訊計量學來做演講,但除了知道資訊計量學是在做什麼的之外,我從老師身上卻有感受到老師對於學門的一種焦慮,
書目計量學bibliometrics (重要概念:布萊德福定律、洛卡定律、齊夫;類別:描述型與行為型書目計量學)
引用、被引用、自我引用,數據的解讀、計算的原則標準其實都是環環相扣,這個真的很不簡單,要如何做到最合乎真實、公平呢?
ps.看著一本厚厚的論文,這個研究方法是我很陌生的一個領域,雖然對於這一類的研究方法早有耳聞,但翻開論文看見公式的部份,就還是依照本能,自然地跳過,也許是離數學很久了吧!不過我想那應該是挺有趣的。
數據的愛恨情愁
學術生產力、引用率、期刊影響指數在近年一直是很HOT的議題,當別人問起你的研究能力如何?這個往往就是最好的證明,醫師、教授升等都需要依賴它,但人們熱愛數據卻也痛恨數據,數據的計算及收錄的標準等背後都隱藏著計多力量在互相拉扯。
學門的焦慮
雖然老師是針對資訊計量學來做演講,但除了知道資訊計量學是在做什麼的之外,我從老師身上卻有感受到老師對於學門的一種焦慮,
書目計量學bibliometrics (重要概念:布萊德福定律、洛卡定律、齊夫;類別:描述型與行為型書目計量學)
引用、被引用、自我引用,數據的解讀、計算的原則標準其實都是環環相扣,這個真的很不簡單,要如何做到最合乎真實、公平呢?
ps.看著一本厚厚的論文,這個研究方法是我很陌生的一個領域,雖然對於這一類的研究方法早有耳聞,但翻開論文看見公式的部份,就還是依照本能,自然地跳過,也許是離數學很久了吧!不過我想那應該是挺有趣的。
Oct 22, 2008
RM 97.10.22
本週課程前半段重點是延續上週命題與假設的練習題,以Yeh,2007的文章,自行設定命題及假設,由Dr.Foster解釋一兩個同學習的練習題後,將上週未說明完的理論及分析的層次繼續說明完畢。(已經連續三個星期上Dr.Foster的課,但有時候在上課中還是會恍神)
感想:
命題及假說雖然就解釋來說都可以理解,但要真的自己寫起來還真的不簡單,不過由於大家在一開始上傳作業花了不少時間(下次應該要由一組中的一個人收集該組同學的,然後再上傳),所以Dr.Foster先以二份同學的作業為範例來講解,包含了概念的範圍和數量、概念與概念間的關係要清楚且明確,命題與假設要有一致性等,原先的一些困惑也得到解答。但還是想說把作業貼上來,請大家協助給予指正喔,謝謝!
已經連續三個星期上Dr.Foster的課,有時候在上課中還是會恍惚,但還是很喜歡Dr.Foster的教授方式,而且跟室友一同討論起研方課的時候,發現別人家的老師都是教研究的方法,而我們的研方則是訓練我們從一開始的命題假設來打好基礎。
感想:
命題及假說雖然就解釋來說都可以理解,但要真的自己寫起來還真的不簡單,不過由於大家在一開始上傳作業花了不少時間(下次應該要由一組中的一個人收集該組同學的,然後再上傳),所以Dr.Foster先以二份同學的作業為範例來講解,包含了概念的範圍和數量、概念與概念間的關係要清楚且明確,命題與假設要有一致性等,原先的一些困惑也得到解答。但還是想說把作業貼上來,請大家協助給予指正喔,謝謝!
已經連續三個星期上Dr.Foster的課,有時候在上課中還是會恍惚,但還是很喜歡Dr.Foster的教授方式,而且跟室友一同討論起研方課的時候,發現別人家的老師都是教研究的方法,而我們的研方則是訓練我們從一開始的命題假設來打好基礎。

ps.因為Yami是母系社會,所以才會第一個proposition
Oct 19, 2008
RM 97.10.15
本週課程前半段重點是延續上週文獻檢閱的部份,評估Yeh,2007,個人給予分數後,與同學特論,最後由Dr.Foster說明他的看法,後半堂則在說明理論的定義以及理論的相關詞彙,例如概念(concepts)、假定(assumptions)、關聯(relationships)等。
感想:
本週感覺到Dr.Foster有刻意地放慢說話的速度,但還是必須要很專注地把耳朵拉大來聽(英文真的要再加強 =.=")。這二週的上課方式,都是老師出作業,回家自己作答,然後課堂上同學討論,再由老師提出個人看法,很喜歡這樣的方式,因為藉由意見交流,可以得知不同的想法,很有收獲。
不過現在可能要先學習的是,了解並可分辨中文學術文獻跟西文學術文獻的差異點,又論文跟期刊的不同,以及有些在認知上覺得重要,而老師們覺得還好,甚至有比其更重要,更需注意的地方。
觀念整理:
理論(theory):將世界的現象用簡單的陳述將其概念化。
假定(assumptions):立基於我們心中已經相信的理念,來描述事件。
命題(Proposition):兩個或兩個以上概念關係的陳述。
假設(Hypothesis):為了解釋一些我們預先想要知道,但還未被實際證據證實過的事件,進而陳述可被驗証或評估之。
練習題:
針對Yeh,2007,給予Proposition及Hypothesis,於下次上課討論。
Ps.在寫此篇的同時,正巧阿猴告訴大家,以後有Dr.Foster都一點半開始上課,很酷!因為我多賺了半小時的學分費。另外上週練習題個人評分如下,跟大家分享,原因就不寫囉!因為Dr.Foster上課都有解釋和釐清。 Title(3);Abstract(4);Introduction(4);Literature review(3);Method(3);Results(4);Conclusion(3) 。
感想:
本週感覺到Dr.Foster有刻意地放慢說話的速度,但還是必須要很專注地把耳朵拉大來聽(英文真的要再加強 =.=")。這二週的上課方式,都是老師出作業,回家自己作答,然後課堂上同學討論,再由老師提出個人看法,很喜歡這樣的方式,因為藉由意見交流,可以得知不同的想法,很有收獲。
不過現在可能要先學習的是,了解並可分辨中文學術文獻跟西文學術文獻的差異點,又論文跟期刊的不同,以及有些在認知上覺得重要,而老師們覺得還好,甚至有比其更重要,更需注意的地方。
觀念整理:
理論(theory):將世界的現象用簡單的陳述將其概念化。
假定(assumptions):立基於我們心中已經相信的理念,來描述事件。
命題(Proposition):兩個或兩個以上概念關係的陳述。
假設(Hypothesis):為了解釋一些我們預先想要知道,但還未被實際證據證實過的事件,進而陳述可被驗証或評估之。
練習題:
針對Yeh,2007,給予Proposition及Hypothesis,於下次上課討論。
Ps.在寫此篇的同時,正巧阿猴告訴大家,以後有Dr.Foster都一點半開始上課,很酷!因為我多賺了半小時的學分費。另外上週練習題個人評分如下,跟大家分享,原因就不寫囉!因為Dr.Foster上課都有解釋和釐清。 Title(3);Abstract(4);Introduction(4);Literature review(3);Method(3);Results(4);Conclusion(3) 。
LIS 97.10.13
本週邀請香港大學教育學院的Prof. Peter Warning,演講題目是Information Policy(資訊政策),主要是說明資訊政策的發展、目的及相關議題。教授講了很多目前的狀況及曾經發生過的事實,在這邊我羅列最有感覺的三點。
Censorship是必要之惡
課堂中教授提到許多關於資訊政策的議題,其中對Censorship最有感覺,因為它無時無刻不存在,從報紙的報導由報社訂定報導的順序、電影的取材拍攝到放映,也需通過審查,各國有各國的政策,甚至是為解決人類資訊保存及近用而存在的圖書館,也是有一定的收錄原則,這也許有某種程度的剝奪人們知的權利,然而為了避免製造不必要驚恐,我得承認它是必要的。
是誰?訂定標準
既然Censorship是必要的,那麼訂定標準的人是誰?標準為何?一個政策的制定是很不容易的,除了要公正、合乎時宜、要顧及該政策與其他政策之間的關係之外,我認為又更重要的一點是,是否會影響人類的知識、資訊發展。
不要侵犯我的隱私權
課堂中老師有提到,美國政府要求圖書館需將每日的讀者借閱記錄,提供給美國政府,造成圖書館很大的反彈。任何一個資訊政策,在不發生立即且明顯的危害之前提下,都不能侵犯到人民的隱私權。假想生活中發生電信業者需提供政府每位人民的通聯記錄及內容,以找出可能、即將成為或隱性潛在的犯罪者,我想那會是一件.........的事(找不到形容詞來形容了)。
ps.其實我想問1997年前的香港、回歸後的資訊政策之改變,以及假想一國兩治五十年後的會有何不同的發展?雖說學術是沒什麼不可以談的,但還是有些顧慮,看來如果真要問就要寫e-mail了。(>.< )
Censorship是必要之惡
課堂中教授提到許多關於資訊政策的議題,其中對Censorship最有感覺,因為它無時無刻不存在,從報紙的報導由報社訂定報導的順序、電影的取材拍攝到放映,也需通過審查,各國有各國的政策,甚至是為解決人類資訊保存及近用而存在的圖書館,也是有一定的收錄原則,這也許有某種程度的剝奪人們知的權利,然而為了避免製造不必要驚恐,我得承認它是必要的。
是誰?訂定標準
既然Censorship是必要的,那麼訂定標準的人是誰?標準為何?一個政策的制定是很不容易的,除了要公正、合乎時宜、要顧及該政策與其他政策之間的關係之外,我認為又更重要的一點是,是否會影響人類的知識、資訊發展。
不要侵犯我的隱私權
課堂中老師有提到,美國政府要求圖書館需將每日的讀者借閱記錄,提供給美國政府,造成圖書館很大的反彈。任何一個資訊政策,在不發生立即且明顯的危害之前提下,都不能侵犯到人民的隱私權。假想生活中發生電信業者需提供政府每位人民的通聯記錄及內容,以找出可能、即將成為或隱性潛在的犯罪者,我想那會是一件.........的事(找不到形容詞來形容了)。
ps.其實我想問1997年前的香港、回歸後的資訊政策之改變,以及假想一國兩治五十年後的會有何不同的發展?雖說學術是沒什麼不可以談的,但還是有些顧慮,看來如果真要問就要寫e-mail了。(>.< )
Oct 9, 2008
RM 97.10.08
本週重點在文獻檢閱,告訴我們為什麼要文獻檢閱,什麼是文獻檢閱、那裡可以找到文獻,以及如何評估文獻(包括標題、摘要、文獻探討、結論等),今天的學習日誌先分三部份,第一部份先寫上課感想,第二部份是將課堂中答錯的地方重新整理記錄,第三部份再寫今天的練習題。
感想:
這是第一次與Dr.Foster做接觸,前面的自我介紹還OK,但進入課程後則要用力地豎起耳朵一個個字聽,才勉強捉到幾個關鍵字(雖然有錄音檔可以反覆聽N遍)。看著下星期的授課重點是第三章的理論與研究,其實有些擔心這部份會更難聽懂,因為這個章節有些地方還滿社會學的。
觀念整理:
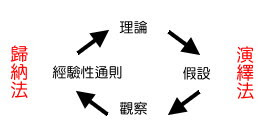
在這裡先把歸納跟演譯用文字及圖像整理一下,好加強加深記憶,雖然明白他們的不同,演譯是由理論出發,歸納是由觀察出發。演繹法或歸納法是思想的運用,而非科學方法,科學方法才是涉及實際運用及操作。
演譯deductive:由抽象的法則推衍出具體現象的陳述之方法
歸納inductive:將具體的個別現象綜合為抽象法則之方法
練習題:
1、參考簡報Where do we find the LIS literature此頁的內容,將圖資學的學術資源列一個清單
這份清單還在不停地編修~~~未完待續!
2、有系統的進行文獻檢索?請你回溯紀錄一次你自己的經驗
遙想大學的報告,我的檢索步驟是
step 1:先至收錄較多社會科學文獻的資料庫中,查詢自己感興趣之主題
step 2:再瀏覽自己感興趣之文獻,記住其可能關鍵字,重新查詢以縮小範圍
step 3:由於資料庫會將不同類型的文獻分類,故我可以先挑選較具參考價值的文獻,進行瀏覽
step 4:如此反覆2~3後,選出主要文獻進行閱讀。
3、評估Yeh,2007,並給予分數,課堂中討論
感想:
這是第一次與Dr.Foster做接觸,前面的自我介紹還OK,但進入課程後則要用力地豎起耳朵一個個字聽,才勉強捉到幾個關鍵字(雖然有錄音檔可以反覆聽N遍)。看著下星期的授課重點是第三章的理論與研究,其實有些擔心這部份會更難聽懂,因為這個章節有些地方還滿社會學的。
觀念整理:
在這裡先把歸納跟演譯用文字及圖像整理一下,好加強加深記憶,雖然明白他們的不同,演譯是由理論出發,歸納是由觀察出發。演繹法或歸納法是思想的運用,而非科學方法,科學方法才是涉及實際運用及操作。
演譯deductive:由抽象的法則推衍出具體現象的陳述之方法
歸納inductive:將具體的個別現象綜合為抽象法則之方法

練習題:
1、參考簡報Where do we find the LIS literature此頁的內容,將圖資學的學術資源列一個清單
這份清單還在不停地編修~~~未完待續!
2、有系統的進行文獻檢索?請你回溯紀錄一次你自己的經驗
遙想大學的報告,我的檢索步驟是
step 1:先至收錄較多社會科學文獻的資料庫中,查詢自己感興趣之主題
step 2:再瀏覽自己感興趣之文獻,記住其可能關鍵字,重新查詢以縮小範圍
step 3:由於資料庫會將不同類型的文獻分類,故我可以先挑選較具參考價值的文獻,進行瀏覽
step 4:如此反覆2~3後,選出主要文獻進行閱讀。
3、評估Yeh,2007,並給予分數,課堂中討論
LIS 97.10.08
本週同樣是邀請本所姐妹校 Univ. of Wisconsin at Milwaukee 穆祥明教授做專題演講,演講題目是Practical Issues in Knowledge Management Informing Infrastructure Design(知識管理知會基礎架構之設計實務),這次主題著重在實際發生案例及運用知識管理於GE的例子,不同於上週,本週則著重在對於不同企業面臨的問題和需求,又知識如何有效地被管理的實務分享。
在這邊想跟大家分享一個案例
我曾經接觸一間很專案管理導向的公司,樣樣事情都以專案方式管理,除了精打細算工項人月外,也要求員工每天寫工作日誌,不光是寫下完成項目、上傳文件檔案之外,也需要將過程寫下來,以做為日後類似工作的參考。雖然那個系統就我看來只是個data storage system.不過因為一些考量,所以沒有提供任何建議給他們,所以最後一個較為理想的解決方案,在這就無法與大家分享。
這家公司的知識管理問題,我想大概除了出在系統面(像倉庫的data storage system、indexing技術不純熟),也包含沒有專業開發人士,主事者認為知識管理系統的開發不能耗費太多人月,當然在推行起來,員工也只是很流水帳的寫著今天完成什麼事,鮮少將過程記錄下來,畢竟要清楚記錄過程是需要花個半小時到一小時不等地工時。
不過滿有趣的一件事來了,老闆認為員工會如此寫流水帳的關係,有一部份是這系統的不健全所造成的。(也許是因為他認為,他已經對於工作記錄寫的好之同事給予小獎勵,大家應該起而效尤才對)
知識管理對企業很重要,不管是大小企業都有這個認知,只是有可能礙於現階段有更重要的目標,而將priority往後,因為隨著人員流動,有很多know how都隨著人員流動而流失,不僅是研發、業務、行政的經驗,也包含企業的人脈,都將隨著人員流動而必須重新花力氣,以再搭起橋樑,也許人脈還是要靠博感情,但知識經驗是一定要保存管理的,也可以做為日後危機處理的相關應變措失。也許大家有一天當上了管理者,對這部份一定會更有感觸。(小蝶老師也在課堂上分享了一個鴻海的故事,也是相當有趣,想到這策略的人腦袋真的轉很快。)
在這邊想跟大家分享一個案例
我曾經接觸一間很專案管理導向的公司,樣樣事情都以專案方式管理,除了精打細算工項人月外,也要求員工每天寫工作日誌,不光是寫下完成項目、上傳文件檔案之外,也需要將過程寫下來,以做為日後類似工作的參考。雖然那個系統就我看來只是個data storage system.不過因為一些考量,所以沒有提供任何建議給他們,所以最後一個較為理想的解決方案,在這就無法與大家分享。
這家公司的知識管理問題,我想大概除了出在系統面(像倉庫的data storage system、indexing技術不純熟),也包含沒有專業開發人士,主事者認為知識管理系統的開發不能耗費太多人月,當然在推行起來,員工也只是很流水帳的寫著今天完成什麼事,鮮少將過程記錄下來,畢竟要清楚記錄過程是需要花個半小時到一小時不等地工時。
不過滿有趣的一件事來了,老闆認為員工會如此寫流水帳的關係,有一部份是這系統的不健全所造成的。(也許是因為他認為,他已經對於工作記錄寫的好之同事給予小獎勵,大家應該起而效尤才對)
知識管理對企業很重要,不管是大小企業都有這個認知,只是有可能礙於現階段有更重要的目標,而將priority往後,因為隨著人員流動,有很多know how都隨著人員流動而流失,不僅是研發、業務、行政的經驗,也包含企業的人脈,都將隨著人員流動而必須重新花力氣,以再搭起橋樑,也許人脈還是要靠博感情,但知識經驗是一定要保存管理的,也可以做為日後危機處理的相關應變措失。也許大家有一天當上了管理者,對這部份一定會更有感觸。(小蝶老師也在課堂上分享了一個鴻海的故事,也是相當有趣,想到這策略的人腦袋真的轉很快。)
Oct 3, 2008
RM 97.10.01
上週介紹完概念,本週上課的重點(Ch6~8)則是在研究設計,從量化與質化的選擇、概念化操作化、測量工具、分析單位、抽樣及信度和效度的部份,這些都是之後進行研究時,所必需考慮的重點,也深深覺得要做出尚屬客觀公正的研究真的是很不簡單。
這次的閱讀範圍的名詞相當多,有些抽樣的概念及方式也很相近,雖然同學解釋的相當清楚,課本也都註記了,但還是覺得自己有必要將隨機抽樣的部份,用自己的話再寫一次,總覺得這個部份特別難記,寫下來日後需要用到的時候,會回想的特別快速且容易。
隨機抽樣
簡單隨機 Simple Random:最單純且易了解的方式,可使用於同質性,個體差異不大的母群體,利用亂數表予以選取直到樣本數足夠為止。
系統抽樣 Systematic Sampling:計算抽樣間距,每隔若干個即抽一個樣本,但需注意單位次序不能和抽樣間隔一致。
分層抽樣 Stratified Sampling:將母體分成幾個次母體,次母體與次母體之間須有顯著的互斥性,比例也必須一致,如無法一致則必須加以權衡。
類聚抽樣 Cluster Sampling:適用於人數眾多,各個體間複雜且異質性高的母群體,不同於分層抽樣的地方在於其次母體與次母體間皆為平均複雜。
感想:今天有兩個地方特別有印象。
第一個是同學的「懂」與「不懂」分類法,真的讓我很驚奇,因為常常一看到一堆詞彙,就會很本能地在心中想到很多大類,然後開始把詞彙扔進自己認為的類別裡,但這件事將在之後時時提醒我,要先從根本面做起。這次的閱讀範圍的名詞相當多,有些抽樣的概念及方式也很相近,雖然同學解釋的相當清楚,課本也都註記了,但還是覺得自己有必要將隨機抽樣的部份,用自己的話再寫一次,總覺得這個部份特別難記,寫下來日後需要用到的時候,會回想的特別快速且容易。
隨機抽樣
簡單隨機 Simple Random:最單純且易了解的方式,可使用於同質性,個體差異不大的母群體,利用亂數表予以選取直到樣本數足夠為止。
系統抽樣 Systematic Sampling:計算抽樣間距,每隔若干個即抽一個樣本,但需注意單位次序不能和抽樣間隔一致。
分層抽樣 Stratified Sampling:將母體分成幾個次母體,次母體與次母體之間須有顯著的互斥性,比例也必須一致,如無法一致則必須加以權衡。
類聚抽樣 Cluster Sampling:適用於人數眾多,各個體間複雜且異質性高的母群體,不同於分層抽樣的地方在於其次母體與次母體間皆為平均複雜。
感想:今天有兩個地方特別有印象。
第二個是本週臨時分組的討論,滿有趣的。有些不懂或似懂非懂的概念,在討論的過程中及同學的報告中,都能得到回饋,遠比自己一個字一個字的「看字」來的有效。
大哉問:教科書的測量、抽樣、信效度其實是還滿具理想性的,但當實際研究後,不曉得會有多少的比例,是必須去妥協或用互補方法來強化研究的信效度。
大哉問:教科書的測量、抽樣、信效度其實是還滿具理想性的,但當實際研究後,不曉得會有多少的比例,是必須去妥協或用互補方法來強化研究的信效度。
LIS 97.10.01
本週邀請到本所姐妹校 Univ. of Wisconsin at Milwaukee 穆祥明教授來訪,演講的主題是Bibliographic Latent Semantic Indexing: No Blames On Users(書目隱性語義索引:使用者無錯),說明除了單純關鍵字比對之外的檢索方式及目前實作的情形(雖然我完全不懂SVD在算什麼)。
人沒有資訊不能活
不知道為什麼在寫這篇心得的時候,我的腦中突然浮現一句大學老師的一句話:「人沒有資訊不能活。」那時還是小大一,聽了沒什麼感覺。但後來發現真的是天天都在處理資訊的問題,對我們更是家常便飯,在這也呼應於第一堂課我們是為解決資訊問題而存在。
是誰在做這件事
隱性語義索引 (LSI:Latent Semantic Indexing)可用來彌補單純關鍵字比對的缺失,將文獻與文獻之間隱含的關係、潛在的「特徵」關聯起來,並解決一詞多義或一義多詞的問題。這使得原本不會從關鍵字查尋得到的資料,得以被發掘,可用來補強現今關鍵字查詢的不足。
在這邊我比較在意的是,是誰去做這件事,找出那些關係跟特徵以及促使我最先看到什麼資訊的人,本身之專業知識是否足夠判斷這件事。就像圖書館選擇買什麼書讀者就看什麼一樣,圖書館用什麼分類讀者就記什麼類號,那些類號對大部份的讀者而言是沒有意義(它只是被放在一個叫494的架子上,然後再記類似的書都放在494的附近),當然也有一些耳聰目明的讀者會很直接地來告訴你「你分錯了!」然而LSI又比類號的判別更需要專業性。
我是為你好
以80/20來說,80%不知道自己要找什麼資料的人,20%有足夠的判斷力知道自己要什麼的人;80%非圖資背景的人,反之20%圖資背景,其中5%是又會找資料的人。簡言之,很多網路服務其實都不是為那20%的人而設計。(但矛盾的是有些地方又像是為那20%的人而量身打造,常常上演我是為你好,你為什麼不要呢的戲碼)
後記:其實一直想要避免自己寫出鬼打牆的心得,但學習的還不夠,所以先盡力地記錄觀察囉。
人沒有資訊不能活
不知道為什麼在寫這篇心得的時候,我的腦中突然浮現一句大學老師的一句話:「人沒有資訊不能活。」那時還是小大一,聽了沒什麼感覺。但後來發現真的是天天都在處理資訊的問題,對我們更是家常便飯,在這也呼應於第一堂課我們是為解決資訊問題而存在。
是誰在做這件事
隱性語義索引 (LSI:Latent Semantic Indexing)可用來彌補單純關鍵字比對的缺失,將文獻與文獻之間隱含的關係、潛在的「特徵」關聯起來,並解決一詞多義或一義多詞的問題。這使得原本不會從關鍵字查尋得到的資料,得以被發掘,可用來補強現今關鍵字查詢的不足。
在這邊我比較在意的是,是誰去做這件事,找出那些關係跟特徵以及促使我最先看到什麼資訊的人,本身之專業知識是否足夠判斷這件事。就像圖書館選擇買什麼書讀者就看什麼一樣,圖書館用什麼分類讀者就記什麼類號,那些類號對大部份的讀者而言是沒有意義(它只是被放在一個叫494的架子上,然後再記類似的書都放在494的附近),當然也有一些耳聰目明的讀者會很直接地來告訴你「你分錯了!」然而LSI又比類號的判別更需要專業性。
我是為你好
以80/20來說,80%不知道自己要找什麼資料的人,20%有足夠的判斷力知道自己要什麼的人;80%非圖資背景的人,反之20%圖資背景,其中5%是又會找資料的人。簡言之,很多網路服務其實都不是為那20%的人而設計。(但矛盾的是有些地方又像是為那20%的人而量身打造,常常上演我是為你好,你為什麼不要呢的戲碼)
後記:其實一直想要避免自己寫出鬼打牆的心得,但學習的還不夠,所以先盡力地記錄觀察囉。
Subscribe to:
Posts (Atom)

